-p-800.avif)
In the field of data modeling, it is remarkable how new cohorts of data engineers and analysts re-discover Kimball's ideas from 25 years ago, often without realizing it!
Let's explore why this is the case and also cover a few drawbacks of this classical approach.
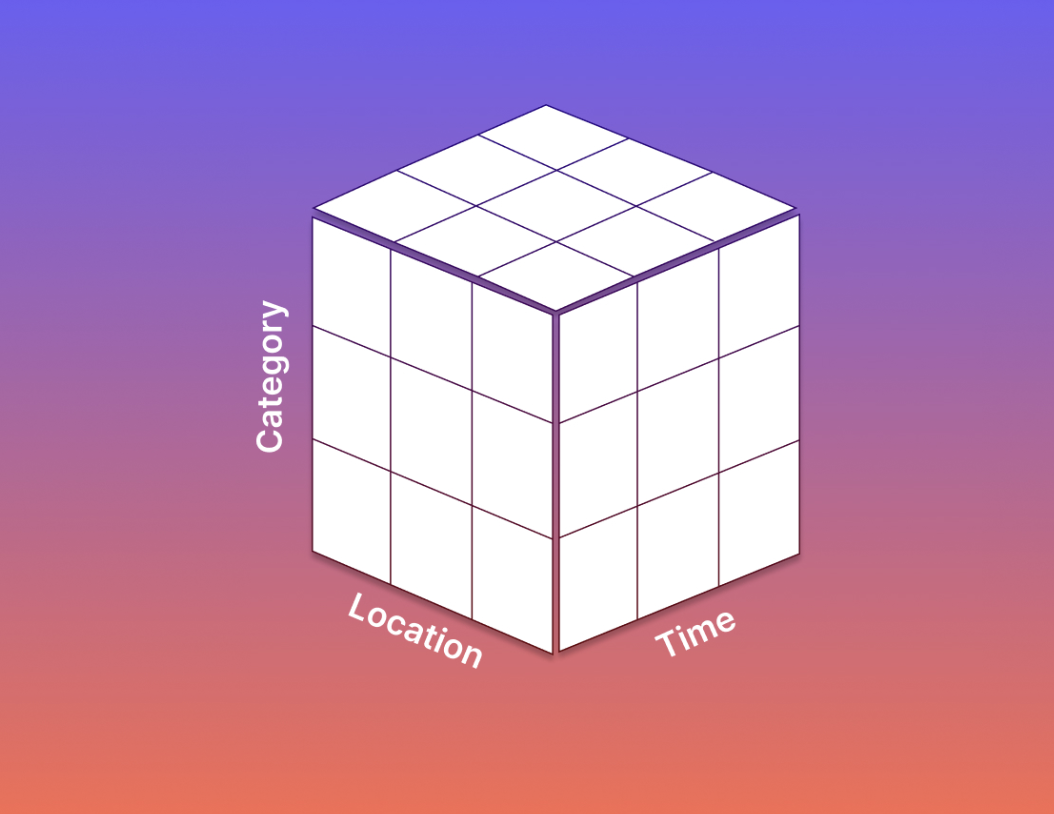
The most common data operations inside an organization involve aggregations to generate metrics and disaggregations to slice, segment, and analyze.
Kimball's modeling framework is well-suited to these operations, with its three main concepts of facts, dimensions, and attributes.
Facts or events are the measurements of interest in a business process, while dimensions are the entities involved in this process, such as time, users, accounts, or products.
These dimensions have their list of properties or attributes, such as a user’s acquisition source or a product’s pricing tier. Attributes are crucial for filtering the facts or generating various segmentation cuts of the aggregated metrics.
Voila! It’s not an accident that new generations of data modelers naturally gravitate to a Kimball-esque representation of their business as these ideas are intuitive. It is a brilliant and time-tested framework to generate metrics, and enable powerful slicing and segmenting of these metrics along several dimensional cuts, including time.